You can instructing a user control that is safe.
<SafeControl
Src="~/_controltemplates/*"
IncludeSubFolders="True"
Safe="True"
AllowRemoteDesigner="True"
/>
You can instructing a user control that is safe.
<SafeControl
Src="~/_controltemplates/*"
IncludeSubFolders="True"
Safe="True"
AllowRemoteDesigner="True"
/>
The uncustomized site page is using a file in file system, and they are executed in compiled mode, so the security is more lex. When it is customized the pages is saved in database, and the security is tightened up. These pages are parsed and processed in a special mode known as safe mode, these is to prevent designer inject is untrustable code into the page. For example, the following page can be run correctly before customized by sharepoint designer, but after customization, it can not be run anymore.
<%@ Page Language="C#" MasterPageFile="~masterurl/default.master"
meta:progid="SharePoint.WebPartPage.Document" %>
<asp:Content ID="main" runat="server"
ContentPlaceHolderID="PlaceHolderMain">
<h3>Page 2</h3>
<% Response.Write("Hello world from server-side script!"); %>
</asp:Content>
In some case, you might want to turn off the protection offered by safe mode, you can do that like the following demo.
<SharePoint>
<SafeMode ... >
<PageParserPaths>
<PageParserPath
VirtualPath="/sites/Sales/SitePages/*"
IncludeSubFolders="true"
CompilationMode="Always"
AllowServerSideScript="true" />
</PageParserPaths>
</SafeMode>
</SharePoint>
Note that a page must be compiled into an assembly DLL to support in-line script, which means that it is not valid to assign a value of Never to the CompilationMode attribute while assigning a value of true to the AllowServerSideScript attribute. Also note that you can assign a value of Auto instead of a value of Always to the CompilationMode attribute. This has the effect of compiling only pages that contain in-line script. When the CompilationMode attribute has a value of Auto, pages without in-line script are still run in no-compile mode.
It is possible to enable in-line script for all site pages within a Web application by configuring the VirtualPath attribute with a value of /* and then setting the CompilationMode attribute to a value of Always or Auto. However, two significant factors should motivate you not to do this.
The first factor is security. By enabling in-line script for all site pages within a Web application, you open the door to attacks on the Web server because any user who has the ability to customize a page can freely write managed code that executes on the Web server.
The second factor pertains to scalability. Earlier in this chapter, I discussed how no-compile pages are more scalable than compiled pages in a large Web application. WSS experiences scaling problems if your Web application attempts to compile and load thousands of assembly DLLs for all of your customized pages. At the very least, you should prefer a CompilationMode setting of Auto instead of Always so that only pages that actually contain script are compiled into assembly DLLs, whereas those pages that do not contain script continue to be parsed and processed in no-compile mode.
Safe mode processing goes a step beyond protecting against in-line script by also considering what controls a user might place on a customized page. For example, imagine a scenario in which a site administrator tries to mount an attack by adding a server-side control to a site page and parameterizing it in a certain way. Safe mode allows the farm administrator to determine which controls can be used in pages that are processed in safe mode.
Customized pages can only contain server-side controls that are explicitly registered as safe controls. Registering a control as a safe control is accomplished by adding a SafeControl entry into the web.config file for the hosting Web application.
<SafeControls>
<SafeControl
Assembly="Microsoft.SharePoint, …"
Namespace="Microsoft.SharePoint.WebControls"
TypeName="*"
AllowRemoteDesigner="True" />
</SafeControls>
If you want to run server control without the above entry, you need to do the following.
<SharePoint>
<SafeMode ... >
<PageParserPaths>
<PageParserPath
VirtualPath="/sites/Sales/*"
AllowUnsafeControls="true" />
</PageParserPaths>
</SafeMode>
</SharePoint>
Note that using this option affects only which server-side controls can be added to a page when customizing a page with a tool, such as the SharePoint Designer. This configuration option does not extend to control instances when users are adding Web Parts to Web Part zones on a page through the browser. Assembly DLLs containing Web Parts must always be explicitly registered by using SafeControl elements for users to be able to place them inside Web Part zones.
A customized site page should be compatible with sharepoint designer, like the following.
<%@ Page MasterPageFile="~masterurl/default.master"
meta:progid="SharePoint.WebPartPage.Document" %>
<asp:Content runat="server" ContentPlaceHolderID="PlaceHolderMain">
<h3>Hello World</h3>
A simple page template used to create site pages
</asp:Content>
The site Page can be added to the site page in site page in sharepoint directly(not wrapped by web part). You can do these using sharepoint designer.
The control need to put in controltemplates in the template folder. To reference it in site page, use the _controltemplates folder like the following.
<%@ Register TagPrefix="luc" TagName="FileViewer"
src="~/_controltemplates/Litware/FileViewer.ascx" %>
There are two ways to deploy web part pages to a site. one is using the elements.xml to define what is inside the web part zone, like the following.
<File Url="WebPartPage.aspx" Name="WebPartPage03.aspx" Type="Ghostable" >
<!-- Add a Web Part to left zone -->
<AllUsersWebPart WebPartZoneID="Left" WebPartOrder="0">
<![CDATA[
<WebPart xmlns="http://schemas.microsoft.com/WebPart/v2"
xmlns:cewp="http://schemas.microsoft.com/WebPart/v2/ContentEditor">
<Assembly>Microsoft.SharePoint, Version=12.0.0.0, Culture=neutral, PublicKeyToken=71e9bce111e9429c</Assembly>
<TypeName>Microsoft.SharePoint.WebPartPages.ContentEditorWebPart</TypeName>
<Title>Yet Another Web Part is Born</Title>
<FrameType>TitleBarOnly</FrameType>
<cewp:Content>
This Web Part was added through declarative logic
</cewp:Content>
</WebPart>
]]>
</AllUsersWebPart>
<!-- Add a Web Part to right zone -->
<AllUsersWebPart WebPartZoneID="Right" WebPartOrder="0">
<![CDATA[
<WebPart xmlns="http://schemas.microsoft.com/WebPart/v2"
xmlns:iwp="http://schemas.microsoft.com/WebPart/v2/Image">
<Assembly>Microsoft.SharePoint, Version=12.0.0.0, Culture=neutral, PublicKeyToken=71e9bce111e9429c</Assembly>
<TypeName>Microsoft.SharePoint.WebPartPages.ImageWebPart</TypeName>
<FrameType>None</FrameType>
<Title>Watch My Gears Run</Title>
<iwp:ImageLink>/_layouts/images/GEARS_AN.GIF</iwp:ImageLink>
</WebPart>
]]>
</AllUsersWebPart>
</File>
Another way is to adding the web parts using code during the feature activating events, like the following.
SPFile page = site.GetFile("SitePages/WebPartPage02.aspx");
SPLimitedWebPartManager mgr = page.GetLimitedWebPartManager(PersonalizationScope.Shared);
// add ContentEditorWebPart to Left Zone
ContentEditorWebPart wp1 = new ContentEditorWebPart();
wp1.Title = "My Most Excellent Title";
wp1.ChromeType = PartChromeType.TitleOnly;
wp1.AllowClose = false;
XmlDocument doc = new XmlDocument();
string ns1 = "http://schemas.microsoft.com/WebPart/v2/ContentEditor";
XmlElement elm = doc.CreateElement("Content", ns1);
elm.InnerText = "This Web Part was added through code";
wp1.Content = elm;
mgr.AddWebPart(wp1, "Left", 0);
// add ImageWebPart Web Part to Right Zone
ImageWebPart wp2 = new ImageWebPart();
wp2.ChromeType = PartChromeType.None;
wp2.ImageLink = @"/_layouts/images/IPVW.GIF";
mgr.AddWebPart(wp2, "Right", 0);
Feature is mechanism that SharePoint used to deploy customized components. The built in components like document list, team site also deployed using feature. So basically, everything can be deployed as feature, for example list definition, content type, site column, workflow and etc, except a site template. The core of the it are two files feature.xml and elements.xml.
When you deploy features, you put all your files into the a folder, and organize the folder with this structure, CONTROLTEMPLATES, FEATURES\FEATURE_NAMES, IMAGES. The content of the folder will copied to the Template folder(c:\program files\common files\microsoft shared\web server extensions\12\Template).
The elements.xml has lots of element. But one of common use is deploying files by using Module element. You can deploy files like the following.
<Module Path="PageTemplates" Url="SitePages" >
<!-- provision standard pages -->
<File Url="Page01.aspx" Type="Ghostable" />
<File Url="Page02.aspx" Type="Ghostable" />
<File Url="Page03.aspx" Type="Ghostable" />
<File Url="Page04.aspx" Type="Ghostable" />
<File Url="Page05.aspx" Type="Ghostable" />
<File Url="Page06.aspx" Type="Ghostable" />
<!-- provision Web Part pages -->
<File Url="WebPartPage.aspx" Name="WebPartPage01.aspx" Type="Ghostable" />
<File Url="WebPartPage.aspx" Name="WebPartPage02.aspx" Type="Ghostable" />
<!-- provision Web Part page with Web Parts inside -->
<File Url="WebPartPage.aspx" Name="WebPartPage03.aspx" Type="Ghostable" >
<!-- Add a Web Part to left zone -->
<AllUsersWebPart WebPartZoneID="Left" WebPartOrder="0">
<![CDATA[
<WebPart xmlns="http://schemas.microsoft.com/WebPart/v2"
xmlns:cewp="http://schemas.microsoft.com/WebPart/v2/ContentEditor">
<Assembly>Microsoft.SharePoint, Version=12.0.0.0, Culture=neutral, PublicKeyToken=71e9bce111e9429c</Assembly>
<TypeName>Microsoft.SharePoint.WebPartPages.ContentEditorWebPart</TypeName>
<Title>Yet Another Web Part is Born</Title>
<FrameType>TitleBarOnly</FrameType>
<cewp:Content>
This Web Part was added through declarative logic
</cewp:Content>
</WebPart>
]]>
</AllUsersWebPart>
<!-- Add a Web Part to right zone -->
<AllUsersWebPart WebPartZoneID="Right" WebPartOrder="0">
<![CDATA[
<WebPart xmlns="http://schemas.microsoft.com/WebPart/v2"
xmlns:iwp="http://schemas.microsoft.com/WebPart/v2/Image">
<Assembly>Microsoft.SharePoint, Version=12.0.0.0, Culture=neutral, PublicKeyToken=71e9bce111e9429c</Assembly>
<TypeName>Microsoft.SharePoint.WebPartPages.ImageWebPart</TypeName>
<FrameType>None</FrameType>
<Title>Watch My Gears Run</Title>
<iwp:ImageLink>/_layouts/images/GEARS_AN.GIF</iwp:ImageLink>
</WebPart>
]]>
</AllUsersWebPart>
</File>
</Module>
A page template, such as default.aspx, is compiled into an assembly dynamic-link library (DLL) and loaded into memory just once per Web application. However, this page template and its efficient usage of memory can still be used to serve up pages for thousands of sites. This is an obvious advantage toward scalability.
When a user customizes a site page by using the SharePoint Designer and then saves those changes, a customized version of the page definition is stored in the content database. While this provides flexibility from a customization standpoint, it also can have a negative impact on performance and scalability. When the customized page is requested, its page definition must be retrieved from the Backend database server by the SPVirtualPathProvider component and then fed to the ASP.NET compiler, where it is parsed and loaded into memory. You can imagine that a Web application with thousands of customized pages requires more memory because each customized page definition must be separately parsed and loaded into memory within the application pool that is hosting the current Web application.
You should note that customized pages are not processed by using the standard ASP.NET model in which a page is compiled into an assembly DLL. Instead, customized pages are parsed by the ASP.NET page parser and then processed using the no-compile mode feature that was introduced with ASP.NET 2.0.
As a developer, your initial reaction to this might be to question why customized pages are processed in no-compile mode. Your instincts likely tell you that compiled pages run faster than no-compile pages. However, no-compile pages can be more efficient and more scalable in certain scenarios. This is especially true in a large WSS environment where the number of customized pages can reach into the thousands or tens of thousands
No-compile pages can be loaded into memory and then unloaded in a manner that is not possible for compiled pages because the .NET Framework doesn’t really support the concept of unloading an assembly DLL from memory. The closest equivalent would be to recycle the current Windows process or the current .NET AppDomain. However, this type of recycling involves unloading all assembly DLLs from memory, not just those assembly DLLs that haven’t been used recently. Furthermore, the .NET Framework places an upper limit on the number of assembly DLLs that can be loaded into a .NET AppDomain.
No-compile pages provide higher levels of scalability because they do not require loading new assembly DLLs or managed classes into memory. Instead, the processing of no-compile pages involves loading control trees into memory. WSS can manage the memory usage for the control trees associated with customized pages more efficiently because they are not compiled into assembly DLLs. For example, once WSS has finished processing a customized page, it can unload the page’s control tree to free up memory for other purposes. Furthermore, nocompile pages eliminate the need to go through the compilation process, which actually provides faster response times for pages upon first access.
<CustomAction Id="HelloApplicationPage"
GroupId="SiteActions"
Location="Microsoft.SharePoint.StandardMenu"
Sequence="2000"
Title="Hello World Application Page"
Description="Getting up and going with inline code">
<UrlAction Url="~site/_layouts/CustomApplicationPages/Hello.aspx"/>
</CustomAction>
Below command can be visible only to site admin
<CustomAction Id="CustomApplicationPage3"
GroupId="SiteActions"
Location="Microsoft.SharePoint.StandardMenu"
Sequence="2003"
Title="Application Page 3"
Description="Admin-only Application page"
RequireSiteAdministrator="True" >
<UrlAction Url="~site/_layouts/CustomApplicationPages/ApplicationPage3.aspx"/>
</CustomAction>
<CustomAction Id="ApplicationPage4.ECBItemMenu"
RegistrationType="List"
RegistrationId="101"
ImageUrl="/_layouts/images/GORTL.GIF"
Location="EditControlBlock"
Sequence="105"
Title="Application Page 4" >
<UrlAction Url="~site/_layouts/CustomApplicationPages/ApplicationPage4.aspx
?ItemId={ItemId}&ListId={ListId}"
/>
</CustomAction>
Under normal conditions, WSS provides error messages intended for end users in a production environment. This means that WSS doesn’t automatically provide rich diagnostic information or helpful error messages to assist you when you are debugging your code. While you are developing WSS components such as custom application pages, you must modify the web.config file for the current Web application to enable debugging support and error messages that contain stack traces. Here’s a fragment of the web.config file that shows the three important attributes that have been changed from their default values to enable rich
<configuration>
<SharePoint>
<SafeMode CallStack="true" />
</SharePoint>
<system.web>
<customErrors mode="Off" />
<compilation debug="true" />
</system.web>
</configuration>
While it is essential to modify the web.config file as shown here to enable debugging support, you will also find it occasionally necessary to return the web.config file to its original state. For example, you might create an application page that throws an exception or an event handler that cancels a user’s actions. By returning the web.config file to its original state, you can see how your code will actually behave in a production environment. Therefore, you should become comfortable with the act of changing the web.config file back and forth between debugging mode and standard end user mode.
In A better javascript constructor, factory, I said factory is a better way to create object. We have seen jQuery can build a jQuery object using factory. But internally jQuery using constructor/prototype. Let me be clear about what do I mean by factory and constructor in javascript. Both factory and constructor can return build object. Factory has a return statement, but constructor has no return statement. Because of this, factory has be called without and without new, the effects are identical. Constructor has to be call with "new". It would return null reference without "new", and moreover it will run in the context of caller, sometimes the caller is global object. Good factory has no such problem, because it's designer's intention be called this way. But internally jQuery use constructor, see my post. Because constructor has use good feature : prototype. but factory can not. the demo code is as below.
function AnimalConstructor() {};
AnimalConstructor.prototype = { name: "fred" }
var an = new AnimalConstructor();
alert(an.name);
AnimalConstructor.prototype.age = 18;
alert(an.age); //show 18
function AnimalFactory() { return { name: "fred" }; };
var b = AnimalFactory();
alert(b.name);
AnimalFactory.prototype.age = 18;
alert(b.age); //show undefined
Why, the object created by factory has no secret link to factory's prototype. The object's constructor is not the factory, in our case the object's constructor is [object Object]. So changing factory's prototype has no effect.
In article From closures to prototypes, part 1 and From closures to prototypes, part 2, there is a comparison between closure and prototype. Now it is recommended to implement a framework using constructor, prototype internally, but as facade it is more user friendly using factory, just like jQuery.
I am fasinated by the jQuery library. I do so much more with so less code. Here I try to mimic jQuery several features: chain operation, extentsion, constructor.
chain operation is pretty easy to mimic. We just need to add "return this;" to the end of a method. Here is my first try
var jQuery = function() {
}
jQuery.prototype =
{
version: "1.0",
showVersion: function() {
alert(this.version);
return this;
},
work: function() {
alert("work");
return this;
}
}
var j = new jQuery();
j.showVersion().work();
Extension is also simple. We just need to decorate its prototype like this
var jQuery = function() {
}
jQuery.prototype =
{
version: "1.0",
showVersion: function() {
alert(this.version);
return this;
},
work: function() {
alert("work");
return this;
}
}
var j = new jQuery();
j.showVersion().work();
jQuery.prototype.sleep = function() {
alert("sleep");
return this;
}
j.sleep();
The constructor is very tricky. First I need to create a jQuery object without "new" keyword. Can we just do this like the following?
var jQuery = function() {
return jQuery.prototype;
}
jQuery.prototype =
{
version: "1.0",
showVersion: function() {
alert(this.version);
return this;
},
work: function() {
alert("work");
return this;
}
}
var j = new jQuery();
j.showVersion().work(); //chain works
jQuery.prototype.sleep = function() {
alert("sleep");
return this;
}
j.sleep(); //extension works
j.version = "2.0";
j.showVersion();
jQuery().showVersion(); //we can create a jQuery object without new, but it show 2.0, it is a singleton.
It works. But seemly, there is a serious bug, that it returns a singleton. So I want to write the following naive code.
var jQuery = function() {
return new jQuery.prototype;
//jQuery.prototype is not a constructor
//return new jQuery.prototype();
//jQuery.prototype is not a constructor
}
It says, jQuery.prototype is not a constructor. so we need a constructor function to do the job.
var jQuery = function() {
return new jQueryConstructor();
}
jQuery.prototype =
{
version: "1.0",
showVersion: function() {
alert(this.version);
return this;
},
work: function() {
alert("work");
return this;
}
}
function jQueryConstructor() {
};
jQueryConstructor.prototype = jQuery.prototype;
//end of library
//following is test code.
var j = new jQuery();
j.showVersion().work(); //chain works
jQuery.prototype.sleep = function() {
alert("sleep");
return this;
}
j.sleep(); //extension works
j.version = "2.0";
j.showVersion();
jQuery().showVersion(); //it shows 1.0, it is not a singleton
Now everything works. But there is a potential that user may change the jQuery.prototype accidentally. let's add a reference jQuery.fn = jQuery.prototype, so that user focus on jQuery.fn, and let jQuery.prototype off attention. So I change the code like the following . Please note that the "return new jQueryConstructor()", you must use "new". Without "new", the prototype "jQueryConstructor.prototype = jQuery.fn" has no use. Here is an artical Create Advanced Web Applications With Object-Oriented Techniques more about the "new".
var jQuery = function() {
return new jQueryConstructor();
}
jQuery.fn = jQuery.prototype =
{
version: "1.0",
showVersion: function() {
alert(this.version);
return this;
},
work: function() {
alert("work");
return this;
}
}
function jQueryConstructor() {
};
//jQueryConstructor.prototype = jQuery.prototype;
jQueryConstructor.prototype = jQuery.fn;
var j = new jQuery();
j.showVersion().work(); //chain works
jQuery.fn.sleep = function() {
alert("sleep");
return this;
}
j.sleep(); //extension works
j.version = "2.0";
j.showVersion();
jQuery().showVersion(); //it shows 1.0, it is not a singleton
Can we make it more simple, yes, let's move the jQueryConstructor into the prototype.
var jQuery = function() {
return new jQuery.fn.init();
}
jQuery.fn = jQuery.prototype =
{
init: function() {},
version: "1.0",
showVersion: function() {
alert(this.version);
return this;
},
work: function() {
alert("work");
return this;
}
}
jQuery.fn.init.prototype = jQuery.fn;
var j = new jQuery();
j.showVersion().work(); //chain works
jQuery.fn.sleep = function() {
alert("sleep");
return this;
}
j.sleep(); //extension works
j.version = "2.0";
j.showVersion();
jQuery().showVersion(); //it shows 1.0, it is not a singleton
Done. I have skeleton of jQuery.
The Animal.init is interesting. "this" refer to Animal function, which can be newed. It shows that function is alsow object, some object can be newed. some can not be newed
function Animal() { };
Animal.prototype = {
name: "Animal",
sayName: function() {
alert(this.name);
}
}
Animal.init = function() {
//"this" refer to Animal function,
//which can be newed. It shows that function
//is alsow object, some object can be newed. some can not be newed
return new this;
}
var an = Animal.init();
an.sayName();
What is wrong with the following code?
function Animal() {
this.name = "fred";
this.say = function() {
alert("my name is " + this.name);
};
}
var an = new Animal();
an.say();
What user accidentally, use the it in the following way? The constructor run in the context of global object, or window object. If you design a framework, this is not good thing.
Animal();
say(); //it pollute the global space
alert(name); //fred
What if user run the following code.
var an = Animal(); //an is undefined because there is no "new" keyword here
an.say();
Following is using factory to do that. It solves the above problem. First, it will not create side effect like pollute the global space, secondly, object can be created with "new" or without.
function Animal() {
var r = { name: "fred" }
r.say = function() {
alert("my name is " + this.name);
};
return r;
}
I call the function with "return" statement , even the statement "return this", factory. function without return is constructor.
I have read a book "Pro JavaScript Techniques", inside it define closure as follow.
Closures are means through which inner functions can refer to the variables present in their outer enclosing function after their parent functions have already terminated.
While it is correct, but if we understand the parent functions as a constructor it is easier. Here is my understanding, closure is feature that we can create a local variable in a constructor, and that variable can be accessed by the created object internally, but it can not be accessed externally. what is unique is that the local variable stay inside a hidden area in the created object. Here is a simple code to demo this.
function Animal(name) {
var r = {};
var local_variable = name;
r.say = function() { alert(local_variable); }
return r;
}
var a = new Animal("jeff");
a.say(); //alert "fred"
alert(a.local_variable); //undefined
If we don't need an object, we just need a function, we can even simplify it like below. In the constructor, name is local variable, the created object is function, this local varible is saved in a hidden area in the function.
function createAlert(name) {
return function() { alert(name); }
}
var say = createAlert("hello");
say();
Closure has another use. Hide the global variable. In the example below, we can have a global variable, it pollutes the environment.
var name = "hello";
function say() { alert(name); }
say();
Now we change to use closure like below.
(function() {
var name = "hello";
this.say = function() { alert(name) };
}
)();
// or
(function(name) {
this.say = function() { alert(name) };
}
)("hello");
say();
At first look, this seems more complicated. we have defined anonymous function, and run the function immediately. This function define a "say" function, and say function reference a local variable. And this variable is not global variable. The benefit of closure is not straight forward here, but it is very important in javascript framework development, because it will cornerstone for encapsulation.
We can add functionality to whole hierarchy by changing the prototype, for example.
function Animal() {
var r = {};
return r;
}
var a = new Animal();
Object.prototype.greet = function() {
alert("hello");
};
a.greet();
When I learned c# long ago, I was told everything in .net is object. I used javascript long before I learned c#. But I have never asked myself this question. Now I ask myself this question. I think everything in javascript is object too.
First let's talk about static object, it can be defined like this. and it can have member variable and method.
var o = {};
//or this, they are the same
//var o = new Object();
o.greet = function () {
alert("hello");
}
Now let's talk about function. I had problem to understand javascript at first, because function is too confusing. Since I came from OO world, I looked at javascript in the eye of OO developer, I tried to map javascript construct into oo construct. In the end, I found that this efford is counter productive, and I decided that javascript function is so unique. We don't have to compare it with c# or java language. But before I have this conclusion, here is my struggle. I think function of javascript can be many thing in traditional OO luanguage. It can be an object, namespace, class, constructor(factory), or function(method). It is such a loose concept.
Here is as sample an function as object, animal is a function, but it is also an object, you can attache member dyanmically.
var animal = function() { };
animal.name = "fred";
animal.say = function() { alert(this.name); }
animal.say();
var Animal = function() {
this.name = "fred";
this.greet = function() {
alert(this.name);
}
}
var a = new Animal();
a.greet();
var Animal = function() {
var r = {};
r.name = "fred";
r.greet = function() { alert(this.name); }
return r;
}
var a = Animal(); //no "new" keyword
a.greet();
function greet()
{
alert("hello");
}
greet();
Javascript function is actual very simple, I shouldn't look at it in traditional view. Instead I should focus on its purpose. I think there are two purpose of function.
As demo before, we can use tradition style consturctor, which return nothing. So it has be called using "new". Otherwise bad thing happend, it will be run in the context of global object. Or we can use factory function. It is safe, because it be called with and without "new".
But our function can have too thing mix purpose together, this is what jQuery does.
For example, $("p.neat").addClass("ohmy").show("slow");
Each function does some job, and return an object, for next function call.
Static object and dyanmic object(function), they both have consturctor.
var o = {};
alert(o.constructor); //function Object(){[native code]}
var animal = function() { return {} };
alert(animal.constructor); //function Function(){ [native code] }
alert(Function.constructor); //function Function(){ [native code] }
But function has prototype, and static object does not have
var o = {};
alert(o.prototype); //undefined
var animal = function() { return {} };
alert(animal.prototype); ////[object Object]
In the world of javascript, everything is object. There is no class. There are two kind of object, one can not create object, let's call it non-constructor object, and one can create object constructor object. Here when I mention constructor, it mean consturctor object. When I mention object, it means all objects including both kinds.
First let's talk about constructor. All object has a constructor, a constructor has a constructor. So can we traverse like this o.constructor.constructor.constructor.... and on and on? Yes, but the final constructor is function Function { [native code] }. Function constructor is itself.
function Dog() { };
var d = new Dog();
alert(d.constructor); //function Dog() {}
alert(d.constructor.constructor); //function Function { [native code] };
alert(d.constructor.constructor.constructor); //function Function { [native code] };
alert(d.constructor.constructor.constructor.constructor); //function Function{ [native code] };
Inheritance implementation in javascript is different from "classical" world. Because there is no such thing "class" in javascript. It use prototype to simulate inheritance. We should know this.
The first user defined constructor is the constructor has no parent. Let call it first level constructor. The prototype of first level consturctor is [object Object], which is non-constructor object, but it has contructor which is the first level constructor itself, which means the prototype is of the constructor created by the constructor. So we can say the first level constructor's prototype is created by the constructor.
function Dog() { this.name = "fred"; }
var d = new Dog();
alert(Dog.prototype); //[object Object]
alert(Dog.prototype.constructor); //function Dog() {}
Now want to simulate the inheritance. So we create second level constructor like this.
function Puppy() { this.age = 18; }
Puppy.prototype = new Dog(); // its prototype is a dog
alert(Puppy.constructor.prototype); //function (){}, but it is actually a dog
var p = new Puppy();
alert(p.name); //it can assess member "name" of it is prototype
alert(p.age);
var p2 = new Puppy();
p2.name = "jeff";
alert(p2.name); //jeff
alert(p.name);
Please note that the object created by the second level constructor can assess the members of of its prototype, which is created by first level constructor. And These members are shared at the beginning, but if it is changed, then a private copy is created at the second level. But the shared copy in the prototype is not changed. In this way, it is memory efficent.
Above we use the pseduoclassical to simulate the inheritance, there is another way to do that, closure. Below is the demo code.
function Dog() {
return { name: "fred" }
}
function Puppy() {
var d = Dog();
d.age = 18;
return d;
}
var p = Puppy();
alert(p.name);
alert(p.age);
Closue is much clean but it is not easy to understand for new javascript developer particularly those from the classical world. Please note that we don't need to use the "new" keyword to to cal the constructor, but we still can. If use the pesudoclassical way, we need to use new, because the constructor does not return an object explicitly
a:link, a:visited, a:hover, a:active, this order can not be reversed, otherwise it won't work. This is due to the cascade rule. If two rules have the same specificity, the last rule to be defined wins out.
a:link, a:visited {text-decoration: none;}
a:hover, a:active {text-decoration: underline;}
Designer tend to dislike link underlines as they add too much weight and visual clutter to a page. If you decide to remove link underlines, you could choose to make links bold instead. That way your page will look less cluttered, but the links will still stand out, and you can then reapply the underlines when the links are hovered over or activated.
a:link, a:visited {
text-decoration: none;
font-weight: bold;
}
a:hover, a:active {
text-decoration: underline;
}
However, it is possible to create a low-impact underline using borders instead. In the following example, the default underline is removed and replaced iwth a less obstuctsive dotted line. When the link is hovered over or clicked, this line turns solid to provide the user with visual feedback that something has happend:
a:link, a:visited {
text-decoration: none;
border-bottom: 1px dotted #000;
}
a:hover, a:active {
border-bottom-style: solid;
}
You can create fancy links iwth image
a:link, a:visited {
color:#666;
text-decoration: none;
background: url(images/underline1.gif) repeat-x left bottom;
}
a:hover, a:active {
background-image: url(images/underline1-hover.gif);
}
You can you attribute selector to style different links.
a[href^="http:"] {
background: url(images/externalLink.gif) no-repeat right top;
padding-right: 10px;
}
a[href^="http://www.yoursite.com"], a[href^="http://yoursite.com"] {
background-image: none;
padding-right: 0;
}
a[href^="mailto:"] {
background: url(images/email.png) no-repeat right top;
padding-right: 10px;
}
a[href^="aim:"] {
background: url(images/im.png) no-repeat right top;
padding-right: 10px;
}
a[href$=".pdf"] {
background: url(images/pdfLink.gif) no-repeat right top;
padding-right: 10px;
}
a[href$=".doc"] {
background: url(images/wordLink.gif) no-repeat right top;
padding-right: 10px;
}
a[href$=".rss"], a[href$=".rdf"] {
background: url(images/feedLink.gif) no-repeat right top;
padding-right: 10px;
}
Here are some guidline how to make your web page more sematic.
<dl>
<dt>Coffee</dt>
<dd>Black hot drink</dd>
<dt>Milk</dt>
<dd>White cold drink</dd>
</dl>
The experience in resolving conflict in anksvn is not so nice. If you commit without get update and you can get a conflict message. If you get conflict message box, you can an update, after that svn will automatically merge your file with the latest version file in server. It also make change make copy copy of original working file and rename it as "*.mine", and get a copy of your original file (eg, *.r43), and a copy of the latest version (eg. *.r44) And this file is marked as "conflict". You can examine the merged file, and manually change whatever is necessary. After that you need to mark it as resolve, before commit. You have 4 choice.
There are two kinds of changes to your working copy. File content changes and tree changes. File change is changing the content of a source controlled file. It is tree changes to rename a file, move a file, add a file, delete a file, rename a directory, move a directory, create a directory, delete a directory.
You don't need to tell subversion that you intend to change a file, jsut make your changes using your text editor, word processor, graphics program, or whatever tool you would nor- mally use. Subversion automatically detects which files have been changed, and in addi- tion, it handles binary files just as easily as it handles text files—and just as efficiently, too.
For tree changes, you can ask Subversion to “mark” files and directories for scheduled removal, addition, copying, or moving. These changes may take place immediately in your working copy, but no additions or removals will happen in the repository until you commit them.
The Subversion commands that you will use here are svn add, svn delete, svn copy, svn move, and svn mkdir.
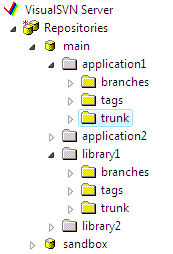
It's a good practice to create one repository for the entire company or department and store all your projects in this repository. Creating separate repository for each project is not a good idea because in that case you will not be able to perform Subversion operations like copy, diff and merge cross-project.
It's not required but usually each projects has 3 subfolders: trunk, branches, tags. The trunk folder contains the main development branch, the branches folder contains subfolders with temporary copies of trunk for experimental development, release stabilization etc. and the tags folder contains copies of the officially released versions.
The EventHandlingScopeActivity is a dramatically different type of event handling activity. It has two discrete sections: a main line child activity and a set of event handling activities. The single main line child activity executes in a normal manner. When the main line activity completes, the entire EventHandlingScopeActivity comes to an end. In addition to the main line child activity, event handling activites are contained within a single EventHandlersActivity that is a child of EventHandlingScopeActivity. The EventHandlerActivity is the parent for one or more EventDrivenActivity instances, with each one activing as a seperate branch of execution. Each EventDrivenActivity contains one or more child activities, but the first child must implement IEventActivity(e.g. HandlingExternalEventActivity) in order to start execution of the branch. When an event is received, the activites within EventDrivenActivty are executed. However, unlike the more common event handling of ListenActivity, the order event branch are all still alive. They can also receive their events and execute the activities within their execution branch. The orginal branch that recived its event cal even receive it again.
These activities are used in advanced scenarios where you need to concurrently handle multiple events and execute a main line set of activities at the same time. In the example that follows, you will implement a workflow using the EventHandlingScopeActivity. It contains a main line set of activities that execute while a condition is true. It also handles three external events, one of which is being used to set the condition for the main line activities.
This article tells me how to setup Profile and Folder Redirection. By default, a profile include redirectable folders which includes Application Data, Desktop, My Documents, and Start Menu. So when you redirect profile withou Folder Redirection settings, the redirectable folders stay inside profile folder. The synchronization between local profile and network profile happens only during login and logout. The good thing is that user's local file operation in the profiles is fast, but the login/logout is slow. Folder redirection makes this reverse, file operation in these folder is synchronized in real time, so that it is not necessary to synchronize folders when login and logout.
The suggested redirection options is that "Create a folder for each user under the root path". Doing this for all the redirectable folders can make them stay together. If you want to change back to let rediretable folder stay with profiles, you can choose "Redirect to the local userprofile location"
So the options are:
So which one should be used? If your network is very heavy or slow, and real time synchronization is not most wanted, choose option 1. If your users care about real time synchronization, for example, the user two computers at the same time. Choose option 2.
using (SchoolDataEntities1 store = new SchoolDataEntities1())
{
var businessDepts = from dep in store.Departments
where dep is DeptBusiness
select dep;
foreach (var item in businessDepts)
{
Console.WriteLine(item.GetType().ToString());
}
}
I am studying RhinoMocks, the new Arrange/Action/Assert style is more concise than the Record/Replay. Compare the style below
public void Analyze_WebServiceThrows_SendsEmail()
{
MockRepository mocks = new MockRepository();
IWebService stubService = mocks.Stub<IWebService>();
IEmailService mockEmail = mocks.CreateMock<IEmailService>();
using (mocks.Record())
{
stubService.LogError("whatever");
LastCall.Constraints(Is.Anything());
LastCall.Throw(new Exception("fake exception"));
mockEmail.SendEmail("a", "subject", "fake exception");
}
LogAnalyzer2 log = new LogAnalyzer2();
log.Service = stubService;
log.Email = mockEmail;
string tooShortFileName = "abc.ext";
log.Analyze(tooShortFileName);
mocks.VerifyAll();
}
[Test]
public void Analyze_WebServiceThrows_SendsEmail_aaa()
{
//arrange
var webServiceStub = MockRepository.GenerateStub<IWebService>();
var emailMock = MockRepository.GenerateStub<IEmailService>();
webServiceStub.Stub
(
x => x.LogError("whatever"))
.Constraints(Is.Anything())
.Throw(new Exception("fake exception")
);
//act
new LogAnalyzer2() { Email = emailMock, Service = webServiceStub }.Analyze("abc.ext");
//assert
emailMock.AssertWasCalled(x => x.SendEmail("a", "subject", "fake exception"));
}
The purpose Of Persistence Ignorance is to keep your domain model decoupled from your persistence layer. Nilsson establishes the following characteristics as things you should not have to do in persistence ignorance
A common pattern in ORM solutions is to force consumers to inherit from a provider-specific base class. The reason for this is dependent on the provider, but typically the base class has some sort of attribute or method required for persistence. This is not a significant problem if you’re designing a system from the ground up, but if you already have a domain model and you’re trying to add persistence, this can be a pain because .NET supports only single inheritance.
Domain Driven theory supports the use of factories when building domain models. We don’t want to have to use a provider-specific factory implementation to create our persistent classes. This couples our model to the ORM instead of keeping it independent, and is usually required by ORM solutions for object tracking and notifications.
This is another pretty typical situation that you’ll see in ORM tools in order for them to provide functionality for out-of-the- box lazy loading. This is so common in the ORM solution world that it doesn’t bother me too much, because you can usually design around this functionality to keep your model independent. However, I can understand the desire to have this as a feature of your ORM.
Similar to base class inheritance, this is another situation in which the ORM engine needs a specific implementation in the persistent classes to do its job. This is obviously a better design, to have to implement an interface instead of having to use up your only class inheritance option in .NET, but you are still tightly coupling your domain model to the ORM, making it less portable.
This is common in ORM solutions so the engine can create instances of your domain model type or reconstitute a particular value. My personal opinion is that having to implement a default constructor doesn’t really violate any major design law. However (and I have yet to see an example this), anything beyond the default constructor implementation would be a significant irritation.
Providing specific types on fields (for example, a GUID for an ID) is sometimes mandatory in ORM frameworks. This is often part of an interface or a base class implementation, and is required in many cases for handling associations and relationships.
This criterion can consist of a forced access modifier on a field or method or can be the metadata used for mapping. A good example of this is using get and set functions as you might in Java versus a property in C#. Additionally, as you will see later, this can also be the use of .NET attributes in your model. Attributes, extraneous methods, base classes, and so forth are a big concern of mine when developing a domain model because I don’t like having to change my well-thought- out access modifiers or pollute my model with some garbage in order for the persistence engine to work.
Real word entity is an independent, seperate, or self-contained existence. It's identity is what gives it uniqueness and differentiates it from other thing else. This is typically a set of characteristics or traits that defines what it is.
Database entity is a table, it's identity is key.
Software identity is representation of a real world identity. But it is not a business object. It is not an extension of database entity, although they have some relevance. It is a modeling effort. According to Evans, the entity is an object that is defined by a "thread of identity that runs though time and often across distinct representations"
It run though times
This means after close the application, and start a new application, an object(entity) can still be reconstructed.
It run across distinct represenations
This means the same object can be consturcted in different machine, or different software
If we find the need to identity an object which runs through the time and across distinct represenation, we need to define it as an entity.
But what exactly is an identity for software entity? In real life, how can people identify me? In real life, I am entity. Although I have an social security number, people do not use it to call identify me. They identify me by name. May be somebody has the same name as me, but they can still identity me, because I still have other fact which is different, for example, my job, my height, color or what ever.
How what is an idenitity in domain model?
Evans says, "When you care only about the ttributes of an element of the model, classify it as a value object." We can think of value object as an object that cannot exist on its own, an object that has no identity by itself. For all intents and purposes, value objects are the parasites of your model because there is no reason or their existence except to describe and associate themselves with our entities. Most of the time, we shouldn’t assign or track their identity for value objects or you will likely impair system performance. These objects are used to describe aspects of the system and so they should, in most cases, be treated as immutable.
According to Merriam-Webster Online, an aggregate is “formed by the collection of units or particles into a body, mass, or amount.” Aggregates, in terms of the domain model, are just that: a logical grouping of entities and value objects into a collection. The reason for aggregation in your model is that complex relationships can lead to data inconsistencies in your application and database.
This concept is simple: the more moving parts in your model, the more likely you are to end up with problems. A case in point is the cleanup of orphaned data and objects. Say, for example, that you have an account record in your database. If you delete the account, you can use a cascading delete to ensure that you don’t have any orphaned data hanging out in other related tables. In the object world, we should forget about the database concept like primary kye, foreign key, cascading update/reference. We need to create aggregate to prevent memory leaking or data store corruption. Our Automobile entity, is the perfect example of an aggregate. The automobile has value objects such as Seats and Tires, and can also have other entity objects such as the Owner object. By this account, the Automobile object becomes the source of the aggregate and for all intents the owner of the group. You may be asking yourself how this helps to enforce referential integrity in your model. The answer actually lies in the structure of your domain model and the objects you expose to consumers. By controlling what objects a consumer can create and by exposing the aggregate, you can ensure integrity in your model. The most common way to enforce this technique is to use the factory pattern discussed later in this chapter and demonstrated in detail in Chapter 8. However, a solid understanding of accessibility modifiers and a well-laid-out hierarchy will also be critical to ensure integrity.
Not everything in our model can be classified as an entity or a value object. Typically in our domain model, a service will be developed as an action or an activity, which doesn’t make sense to build into our entities or value objects.
Some concepts from the domain aren’t natural to model as objects. Forcing the required domain functionality to be the responsibility of an Entity or Value either distorts the definition of a model-based object or adds meaningless artificial objects. - Eric Evans
Continuing with the automobile example, suppose the automobile informs you when it is time to change oil. This service requires the evaluation of a series of domain objects and thresholds to determine that it is time for an oil change. Although the service is expressed by using Automobile entity (technically an aggregate), it wouldn’t make sense to encapsulate it as that object. This service interface needs to be outside the entity and value to keep it reusable.
Service does not only reside in domain layer, it can also reside in other layer such as application, infrastructure. Service is a natual object concept, its purpose is to build functions in as much reusability as possible, and encapsulate outside the implementation of our value and entity objects.
At its worst, business logic can be very complex. Rules and logic describe many different cases and slants of behavior, and it’s this complexity that objects were designed to work with. A Domain Model creates a web of interconnected objects, where each object represents some meaningful individual, whether as large as a corporation or as small as a single line on an order form. —Martin Fowler
The domain model is much more than just an object model because its creation is rooted in the collaboration among the experts in the organization. Specifically, the domain model is the conceptual layer that can be used to represent the process as a whole and is fundamentally a mechanism that can bring the people in the software life cycle closer together. Similar to UML acting as a common vocabulary, a completed domain model can also be a catalyst for enhanced cross-process and cross-functional communication.
As an example, take Company X, comprising a handful of new developers, a few senior developers, some quality control people, a couple of business analysts, and a project manager (in other words, a rather typical development team). Suppose that the developer and business analysts have a hard time getting anything done because the developers don’t really understand the nuances of banking and likewise the business analysts can’t explain things effectively to the technical personnel. To overcome these communication problems, Company X has implemented a Software Development Life Cycle (SDLC) process, involving reams of paper defining specific problems and development needs for the current system. The quality control (QC) people resent the developers because the developers have never adequately explained the situation from an impact standpoint, and the project manager is frustrated because the communication issues are reducing the time he is able to spend on the golf course.
Now, give this team a robust domain model that conceptualizes the realm of interactions in the software, and many of these communication issues disappear. The UML (or any common modeling language) used to diagram the domain is a common way for everyone to communicate. The domain model itself can be used to explain complex interactions from a functional and a technical perspective.
When you are working on modeling a business domain, don’t get hung up on formalized UML in meetings with the domain experts. The UML should not become an obstacle in development. Instead, it should help people communicate by using a common lexicon. The easiest way to build a good domain model is with paper and pencil or a whiteboard. We can use rudimentary notation that everyone can understand, demonstrating the relationships and behavior within the model. After the initial meetings, we take the whiteboard drawing and use a formal modeling tool and add any formal notation that we may have glossed over in the meeting.
The best way to do it is to make software a reflection of the domain. Software needs to incorporate the core concepts and elements of the domain, and to precisely realize the relations between them. Sofeware has to model the domain.
Somebody without knowledge of banking should be able to learn a lot just buy reading the code in a domain model. This is essential. Software which does not have its roots planted deep into the the domain will not react well to change over time.
We need to create an abstraction of the domain. It is a domain model. It is not a particular diagram, it is the idea that the diagram is intended to convey. It is not just the knowledge in a domain expert's head, It is a rigorously organized and selective abstraction of that knowledge. It can be in the form a diagram , carefully written code or just english sentence.
A specific domain could be more than a human can handle at one time. We need to orgainze information, to systematize, to divid it up in smaller pieces, to group those pieces into logical modules, and take one at a time and deal with it.
A model is the essence of the software, but need to create ways to express it, to communicate it with others. We need to cummunicate the model. There are different ways to do that. One is graphical: diagrams, use cases, drawings, pictures, etc. Another is writing. We write down our vision about the domain. Another is language. We can and we should create a language to communicate specific issues about the domain. The right way to design software is domain driven design. It combines design and development practice, and shows how design and development can work together to create a better solution. Good design will accelerate the development, while feed back coming from the development process will enhance the design.
You and the domain experts need to exchanging knowledge. You start asking questions, and they respond. While do do that, they dig essential concepts out of the domain. Those concepts may come out unpolished and disorganized, but nonetheless they are essential for understanding the domain. You need to learn as much as possible about the domain from the experts. And by putting the right questions, and processing the information in the right way, you and the experts will start to sketch a view of the domain, a domain model. This view is neither complete nor correct, but it is the start you need. Try to figure out the essential concepts of the domain. This is an important part of the design. Usually there are long discussions between software architects or developers and the domain experts. The software specialists want to extract knowledge from the domain experts, and they also have to transform it into a useful form. At some point, they might want to create an early prototype to see how it works so far. While doing that they may find some issues with their model, or their approach, and may want to change the model. The communication is not only one way, from the domain experts to the software architect and further to the developers. There is also feedback, which helps create a better model, and a clearer and more correct understanding of the domain. Domain experts know their area of expertise well, but they organize and use their knowledge in a specific way, which is not always the best to be implemented into a software system. The analytical mind of the software designer helps unearth some of the key concepts of the domain during discussions with domain experts, and also help construct a structure for future discussions as we will see in the next chapter. We, the software specialists (software architects and developers) and the domain experts, are creating the model of the domain together, and the model is the place where those two areas of expertise meet. This might seem like a very time consuming process, and it is, but this is how it should be, because in the end the software’s purpose is to solve business problems in a real life domain, so it has to blend perfectly with the domain.
After we create a great model, we need to implement the model in code, propertyly transfer it into code. Any domain can be expressed with many models, and any model can be expressed in various ways in code. For each particular problem there can be more than one solution. Which one do we choose? Having one analytically correct model does not mean the model can be directly expressed in code. Or maybe its implementation will break some software design principles, which is not advisable. It is important to choose a model which can be easily and accurately put into code. The basic question here is: how do we approach the transition from model to code?
It happens that software analysts work with business domain experts for months, discover the fundamental elements of the domain, emphasize the relationshipbs between them, and create a correct model, which accurately captures the domain. Then the model is passed on to the software developers. The developers might look at the model and discover that some of the concepts or relationships found in it cannot be properly expressed in code. So they use the model as the original source of inspiration, but they create their own design which borrows some of the ideas from the model, and adds some of their own. The development process continues further, and more classes are added to the code, expanding the divide between the original model and the final implementation. The good end result is not assured. Good developers might pull together a product which works, but will it stand the trials of time? Will it be easily extendable? Will it be easily maintainable?
Any domain can be expressed with many models, and any model can be expressed in various ways in code. For each particular problem there can be more than one solution. Which one do we choose? Having one analytically correct model does not mean the model can be directly expressed in code. Or maybe its implementation will break some software design principles, which is not advisable. It is important to choose a model which can be easily and accurately put into code. The basic question here is: how do we approach the transition from model to code?
One of the recommended design techniques is the so called analysis model, which is seen as separate from code design and is usually done by different people. The analysis model is the result of business domain analysis, resulting in a model which has no consideration for the software used for implementation. Such a model is used to understand the domain. A certain level of knowledge is built, and the model resulting may be analytically correct. Software is not taken into account at this stage because it is considered to be a confusing factor. This model reaches the developers which are supposed to do the design. Since the model was not built with design principles in mind, it probably won’t serve that purpose well. The developers will have to adapt it, or to create a separate design. And there is no longer a mapping between the model and the code. The result is that analysis models are soon abandoned after coding starts.
One of the main issues with this approach is that analysts cannot foresee some of the defects in their model, and all the intricacies of the domain. The analysts may have gone into too much detail with some of the components of the model, and have not detailed enough others. Very important details are discovered during the design and implementation process. A model that is truthful to the domain could turn out to have serious problems with object persistence, or unacceptable performance behavior. Developers will be forced to make some decisions on their own, and will make design changes in order to solve a real problem which was not considered when the model was created. They create a design that slips away from the model, making it less relevant.
If the analysts work independently, they will eventually create a model. When this model is passed to the designers, some of the analysts’ knowledge about the domain and the model is lost. While the model might be expressed in diagrams and writing, chances are the designers won’t grasp the entire meaning of the model, or the relationships between some objects, or their behavior. There are details in a model which are not easily expressed in a diagram, and may not be fully presented even in writing. The developers will have a hard time figuring them out. In some cases they will make some assumptions about the intended behavior, and it is possible for them to make the wrong ones, resulting in incorrect functioning of the program.
Analysts have their own closed meetings where many things are discussed about the domain, and there is a lot of knowledge sharing. They create a model which is supposed to contain all that information in a condensed form, and the developers have to assimilate all of it by reading the documents given to them. It would be much more productive if the developers could join the analyst meetings and have thus attain a clear and complete view of the domain and the model before they start designing the code.
A better approach is to closely relate domain modeling and design. The model should be constructed with an eye open to the software and design considerations. Developers should be included in the modeling process. The main idea is to choose a model which can be appropriately expressed in software, so that the design process is straightforward and based on the model. Tightly relating the code to an underlying model gives the code meaning and makes the model relevant.
Getting the developers involved provides feedback. It makes sure that the model can be implemented in software. If something is wrong, it is identified at an early stage, and the problem can be easily corrected.
Those who write the code should know the model very well, and should feel responsible for its integrity. They should realize that a change to the code implies a change to the model; otherwise they will refactor the code to the point where it no longer expresses the original model. If the analyst is separated from the implementation process, he will soon lose his concern about the limitations introduced by development. The result is a model which is not practical.
Any technical person contributing to the model must spend some time touching the code, whatever primary role he or she plays on the project. Anyone responsible for changing code must learn to express a model through the code. Every developer must be involved in some level of discussion about the model and have contact with domain experts. Those who contribute in different ways must consciously engage those who touch the code in a dynamic exchange of model ideas through the Ubiquitous Language.
If the design, or some central part of it, does not map to the domain model, that model is of little value, and the correctness of the software is suspect. At the same time, complex mappings between models and design functions are difficult to understand and, in practice, impossible to maintain as the design changes. A deadly divide opens between analysis and design so that insight gained in each of those activities does not feed into the other.
Design a portion of the software system to reflect the domain model in a very literal way, so that mapping is obvious. Revisit the model and modify it to be implemented more naturally software, even as you seek to make it reflect deeper insight in the domain. Demand a single model that serves both purpose well, in addition to supporting a fluent Ubiquitous Language.
Draw from the model the terminology used in the design and the basic assignment of responsibilities. The code becomes an expression of the model, so a change to the code may be a change to the model. Its effect must ripple through the rest of the project’s activities accordingly.
To tightly tie the implementation to a model usually requires software development tools and languages that support a modeling paradigm, such as object-oriented programming.
When we create a software application, a large part of the application is not directly related to the domain, but it is part of the infrastructure or serves the software itself. It is possible and ok for the domain part of an application to be quite small compared to the rest, since a typical application contains a lot of code related to database access, file or network access, user interfaces, etc.
In an object-oriented program, UI, database, and other support code often gets written directly into the business objects. Additional business logic is embedded in the behavior of UI widgets and database scripts. This some times happens because it is the easiest way to make things work quickly.
However, when domain-related code is mixed with the other layers, it becomes extremely difficult to see and think about. Superficial changes to the UI can actually change business logic. To change a business rule may require meticulous tracing of UI code, database code, or other program elements. Implementing coherent, model-driven objects becomes impractical. Automated testing is awkward. With all the technologies and logic involved in each activity, a program must be kept very simple or it becomes impossible to understand.
Therefore, partition a complex program into LAYERS. Develop a design within each LAYER that is cohesive and that depends only on the layers below. Follow standard architectural patterns to provide loose coupling to the layers above. Concentrate all the code related to the domain model in one layer and isolate it from the user interface, application, and infrastructure code. The domain objects, free of the responsibility of displaying themselves, storing themselves, managing application tasks, and so forth, can be focused on expressing the domain model. This allows a model to evolve to be rich enough and clear enough to capture essential business knowledge and put it to work.
User Interface (Presentation Layer)
Responsible for presenting information to the user and interpreting user commands.
Application Layer
This is a thin layer which coordinates the application activity. It does not contain business logic. It does not hold the state of the business objects, but it can hold the state of an application task progress.
Domain Layer
This layer contains information about the domain. This is the heart of the business software. The state of business objects is held here. Persistence of the business objects and possibly their state is delegated to the infrastructure layer.
Infrastructure Layer
This layer acts as a supporting library for all the other layers. It provides communication between layers, implements persistence for business objects, contains supporting libraries for the user interface layer, etc.
It is important to divide an application in separate layers, and establish rules of interactions between the layers. If the code is not clearly separated into layers, it will soon become so entangled that it becomes very difficult to manage changes. One simple change in one section of the code may have unexpected and undesirable results in other sections. The domain layer should be focused on core domain issues. It should not be involved in infrastructure activities. The UI should neither be tightly connected to the business logic, nor to the tasks which normally belong to the infrastructure layer. An application layer is necessary in many cases. There has to be a manager over the business logic which supervises and coordinates the overall activity of the application.
There is a category of objects which seem to have an identity, which remains the same throughout the states of the software. For these objects it is not the attributes which matter, but a thread of continuity and identity, which spans the life of a system and can extend beyond it. Such objects are called Entities
Therefore, implementing entities in software means creating identity. For a person it can be a combination of attributes: name, date of birth, place of birth, name of parents, current address. The Social Security number is also used in US to create identity. For a bank account the account number seems to be enough for its identity. Usually the identity is either an attribute of the object, a combination of attributes, an attribute specially created to preserve and express identity, or even a behavior. It is important for two objects with different identities to be to be easily distinguished by the system, and two objects with the same identity to be considered the same by the system. If that condition is not met, then the entire system can become corrupted.
We may be tempted to make all objects entities. Entities can be tracked. But tracking and creating identity comes with a cost. We need to make sure that each instance has its unique identity, and tracking identity is not very simple
If we don't need to keep track of an object, then it is value objects.
A value object can be immutable or mutable. But it is highly recommended that value objects be immutable. They are created with a constructor, and never modified during their life time.When you want a different value for the object, you simply create another one. This has important consequences for the design. Being immutable, and having no identity, Value Objects can be shared. That can be imperative for some designs. Immutable objects are sharable with important performance implications. They also manifest integrity, i.e. data integrity. Imagine what it would mean to share an object which is not immutable. An air travel booking system could create objects for each flight. One of the attributes could be the flight code. One client books a flight for a certain destination. Another client wants to book the same flight. The system chooses to reuse the object which holds the flight code, because it is about the same flight. In the meantime, the client changes his mind, and chooses to take a different flight. The system changes the flight code because this is not immutable. The result is that the flight code of the first client changes too.
One golden rule is: if Value Objects are shareable, they should be immutable. Value Objects should be kept thin and simple. When a Value Object is needed by another party, it can be simply passed by value, or a copy of it can be created and given. Making a copy of a Value Object is simple, and usually without any consequences. If there is no identity, you can make as many copies as you wish, and destroy all of them when necessary.
A Service should not replace the operation which normally belongs on domain objects. We should not create a Service for every operation needed. But when such an operation stands out as an important concept in the domain, a Service should be created for it. There are three characteristics of a Service:
When a significant process or transformation in the domain is not a natural responsibility of an Entity or Value Object, add an operation to the model as a standalone interface declared as a Service. Define the interface in terms of the language of the model and make sure the operation name is part of the Ubiquitous Language. Make the Service stateless.
While using Services, is important to keep the domain layer isolated. It is easy to get confused between services which belong to the domain layer, and those belonging to the infrastructure. There can also be services in the application layer which adds a supplementary level of complexity. Those services are even more difficult to separate from their counterparts residing in the domain layer. While working on the model and during the design phase, we need to make sure that the domain level remains isolated from the other levels.
Both application and domain Services are usually built on top of domain Entities and Values providing required functionality directly related to those objects. Deciding the layer a Service belongs to is difficult. If the operation performed conceptually belongs to the application layer, then the Service should be placed there. If the operation is about domain objects, and is strictly related to the domain, serving a domain need, then it should belong to the domain layer.
